
.jpg)


数据结构
一、数据结构概述
一、定义
我们如何把现实中大量而复杂的问题以特定的数据类型和特定的存储结构保存到主存储器(内存)中,以及在此基础上为实现某个功能(比如查找某个元素,删除某个元素,对所有元素进行排序)而执行的相应操作,这个相应的操作也叫算法
数据结构 = 个体 + 个体的关系
算法 = 对存储数据的操作
二、算法
解题的方法和步骤
衡量算法的标准:
1. 时间复杂度
大概程序要执行的次数,而非执行的时间
2. 空间复杂度
算法执行过程中大概所占用的最大内存
3. 难易程度
4. 健壮性
三、数据结构的地位
数据结构是软件中最核心的课程
程序 = 数据的存储 + 数据的操作 + 可以被计算机执行的语言
四、预备知识
一、指针
1、指针的重要性:
指针是C语言的灵魂
2、定义
地址:
内存单元的编号
从0开始的非负整数
范围:0 -- FFFFFFFF【0-4G-1】
指针:
指针就是地址 地址就是指针
指针变量就是存放内存单元地址的变量
指针的本质是一个操作受限的非负整数
3、分类
1、基本类型的指针


/**
* @author : guqinge
* @date : 2023/11/25
* @description :
*/
# include <cstdio>
void f(int * p) //不是定义了一个名字叫做 *p 的形参,而是定义了一个形参, 该形参名字叫做 ip ,它的类型是 int *
{
*p = 100;
}
int main(void)
{
int i = 9;
f(&i);
printf("i = %d\n", i);
return 0;
}注意:
指针变量也是变量,只不过它存放的不能是内存单元的内容,只能存放内存单元的地址
普通变量前不能加 *
常量和表达式前不能加 &
2、指针和数组的关系
指针和一维数组
一维数组名
一维数组名是个指针常量
它存放的是一维数组第一个元素的地址
下标和指针的关系
如果p是个指针变量,则 p[i] 永远等价于 *(p+i)
确定一个一维数组需要几个参数【如果一个函数要处理一个一维数组,则需要接收该数组的哪些信息】
需要两个参数:
数组第一个元素的地址
数组的长度
/**
* @author : guqinge
* @date : 2023/11/25
* @description : 数组
*/
# include <cstdio>
int main(void)
{
int a[5] = {1,2,3,4,5}; //a[3] == *(a+3);
printf("%p\n", a+1); //%p输出指针本身的值
printf("%p\n", a+2);
printf("%d\n", *a+3); // *a+3等价于 a[0] + 3
// ,就是a指向的是第一个元素,如果是 *(a+1)那就是指向的第二个元素,就是a[1],因为下标是从0开始的
// 所以 *a+3就等价于a[0]+3或者是,或者说是a[3]
// 内部其实是这样计算的,如果存放的是 int 类型的数据,那么数组名即指针变量a指向的就是前4个字节, *(a+1) 就表示指向的后4个字节,如果后面还有就每4个字节往后找
// 如果存放的是char类型的数据,首元素指向的就是第一个字节, 后面的元素每个元素跨越1个字节去找
// 所以数组只存放了第一个元素的地址,但是可以根据第一个元素的地址,计算出后面元素的地址
// 所以界定一个数组,只需要首元素地址和数组长度即可
return 0;
}/**
* @author : guqinge
* @date : 2023/11/25
* @description : 数组
*/
# include <cstdio>
void show_Array(int * p, int len)
{
int i = 0;
for (i = 0; i < len; ++i)
printf("%d\n", p[i]);
//p[0] = -1; //p[0] 等价于与 *p p[2] 等价于 *(p+2) 等价于 *(a+2) 等价于 a[2]
//p[i] 就是主函数的 a[i]
}
int main(void)
{
int a[5] = {1,2,3,4,5};
show_Array(a, 5); //a等价于&a[0], &a[0]本身就是int *类型
//printf("%d\n", a[0]); // -1
return 0;
}指针变量的运算
指针变量不能相加 不能相乘 也不能相除
如果两个指针变量指向的是同一块连续空间中的不同存储单元,则这两个指针变量才可以相减
指针变量可以加减一整数,前提是最终结果不能超过指针
p+i 的值是 p+i*(p所指向的变量所占的字节数)
p-i 的值是 p-i*(p所指向的变量所占的字节数)
p++ <==> p+1
p-- <==> p-1
一个指针变量到底占几个字节【非重点】
预备知识:
sizeof(数据类型)
功能:返回值就是该数据类型所占字节数
例子:
sizeof(int) = 4
sizeof(char) = 1
sizeof(double) = 8
sizeof(变量名)
功能:返回值是该变量所占的字节数
假设p指向char类型变量(1个字节)
假设q指向int类型变量(4个字节)
假设r指向double类型变量(8个字节)
请问: p q r 本身所占的字节数是否一样?
答案:p q r 本身所占的字节数是一样的
总结:
一个指针变量,无论它指向的变量占几个字节,该指针变量本身只占四个字节
一个变量的地址是用该变量首字节的地址来表示
4、所有指针变量只占4个字节,用第一个字节的地址表示整个变量的地址
/**
* @author : guqinge
* @date : 2023/11/26
* @description :
*/
# include <cstdio>
int main(void)
{
double * p;
double x = 66.6;
p = &x; //x占8个字节, 1个字节是8位, 1个字节一个地址
// 因为一个字节占8位,就是一个地址。 所以p存放的只是一个地址,通常就是首个字节
double arr[3] = {1.1, 2.2, 3.3};
double * q;
q = &arr[0];
printf("%p\n", q); //0x16d13abe0 %p 实际就是以十六进制输出
q = &arr[1];
printf("%p\n", q); //0x16d13abe8 0x16d13abe8 - 0x16d13abe0 = 8
return 0;
}
注意:一个指针变量无论它指向的变量占几个字节,它本身所占的字节都是固定的,指针变量统一的只占4个字节
二、结构体
一、为什么会出现结构体
为了表示一些复杂的数据,而普通的基本类型变量无法满足要求
二、什么叫结构体
结构体是用户根据实际需要然后自己定义的复合数据类型
# include <cstdio>
# include <string.h>
struct Student
{
int sid;
char name[200];
int age;
}; //分号不能省略
int main(void)
{
struct Student ts = {1000, "zhangsan", 20};
printf("%d %s %d\n", st.sid, st.name, st.age);
st.sid = 99;
st.name = "list"; //error c语言中不能这样写
strcpy(st.name, "list");
st.age = 22;
printf("%d %s %d\n", st.sid, st.name, st.age);
return 0;
}三、如何使用结构体
两种方式:
struct Student ts = {1000, "zhangsan", 20};
struct Student * pst = &st;
st.sid
pst -> sid
a. 这个表示 pst 所指向的结构体变量中的sid这个成员
# include <cstdio>
struct Student
{
int sid;
char name[200];
int age;
}; //分号不能省略
int main(void)
{
struct Student st = {1000, "zhangsan", 20};
//st.sid = 99; //第一种方式
struct Student * pst;
pst = &st;
pst -> sid = 99; //pst -> sid 等价于 (*pst).sid, 而(*pst).sid 等价于 st.sid , 所以pst -> sid 等价于 st.sid
return 0;
}四、注意事项
结构体变量不能加减乘除,但可以相互赋值
普通结构体变量和结构体指针变量作为函数传参的问题
/**
* @author : guqinge
* @date : 2023/11/26
* @description : 普通结构体变量和结构体指针变量作为函数传参的问题
*/
# include <cstdio>
# include <cstring>
void f(struct Student * pst);
//void g(struct Student st);
void g2(struct Student * pst);
struct Student
{
int sid;
char name[200];
int age;
}; //分号不能省略
int main(void)
{
struct Student st; //已经为st分配好了内存
f(&st);
//printf("%d %s %d\n", st.sid, st.name, st.age);
g2(&st);
return 0;
}
void f(struct Student * pst)
{
//(*pst).sid = 99;
pst -> sid = 100;
strcpy(pst -> name, "ldlili");
pst -> age = 18;
}
//这种方式耗内存,耗时间,不推荐(因为直接传 struct Student st 至少需要占208个字节, 而传递指针变量只需要占4个字节)
//void g(struct Student st)
//{
// printf("%d %s %d\n", st.sid, st.name, st.age);
//}
void g2(struct Student * pst)
{
printf("%d %s %d\n", pst->sid, pst->name, pst->age);
}三、动态内存的分配


/**
* @author : guqinge
* @date : 2023/11/28
* @description : 动态内存分配
*/
# include <cstdio>
# include <cstdlib>
int main(void)
{
int a[5] = {4, 10, 2, 8, 6};
int i;
int len;
printf("请输入您需要分配的数组的长度:len =");
scanf("%d", &len);
int * pArr = (int *) malloc(sizeof(int) * len); //malloc函数只返回第一个字节地址,强转为 int *类型是为了告诉编译器,把第一个字节的地址,当做一个整形的地址,就是第一个字节的地址当做4个字节的地址,那么pArr+1就指向了后四个字节了
// *pArr = 4; //类似于 a[0] = 4;
// pArr[1] = 10; //类似于a[1] = 10;
// printf("%d %d\n", *pArr, pArr[1]);
//可以把pArr当做一个普通数组来使用
for (i = 0; i < len; ++i)
scanf("%d", &pArr[i]);
for (i = 0; i < len; ++i)
printf("%d\n", *(pArr+i));
free(pArr); //把pArr所代表的动态分配的20个字节的内存释放
return 0;
}二、模块一:线性结构【把所有的结点用一根直线串起来】
1、连续存储[数组]
1.什么叫数组
元素类型相同,大小相等
2.数组的优缺点
3、连续存储数组的算法演示
/**
* @author : guqinge
* @date : 2023/12/4
* @description : 数组
*/
# include <cstdio>
# include <cstdlib>
//定义了一个数据类型,该数据类型的名字叫做struct Arr,该数据类型含有三个成员,分别是pBase,len,cnt
struct Arr
{
int * pBase; //存储的是数组第一个元素的地址
int len; //数组所能容纳的最大元素的个数
int cnt; //当前数组有效元素的个数
//int increment; //自动增长因子 这个需要学过动态内存的扩充,需要allocate()这个函数,比较复杂,这里不讲
};
void init_arr(struct Arr * pArr, int length); //初始化方法
bool append_arr(struct Arr * pArr, int val); //追加元素
bool insert_arr(struct Arr * pArr, int pos, int val); //指定下标新增元素. pos的值从1开始
bool delete_arr(struct Arr * pArr, int pos, int * pVal); //删除元素; *pVal用来接收删除成功的值
int get(struct Arr * pArr, int pos); //或者指定下标元素; pos的值从1开始
bool is_empty(struct Arr * pArr); //数组是否为空
bool is_full(struct Arr * pArr); //数组是否已满
void sort_arr(struct Arr * pArr); //排序
void show_arr(struct Arr * pArr); //输出
void inversion_arr(struct Arr * pArr); //元素倒置
int main(void)
{
struct Arr arr;
int val;
init_arr(&arr, 6);
append_arr(&arr,2);
append_arr(&arr,6);
insert_arr(&arr,1,222);
append_arr(&arr,1);
append_arr(&arr,5);
delete_arr(&arr,1,&val);
int result = get(&arr,2);
printf("获取到的元素是:%d\n", result);
inversion_arr(&arr);
printf("倒置之后的数组内容是是:\n");
show_arr(&arr);
sort_arr(&arr);
printf("排序之后的数组内容是是:\n");
// append_arr(&arr,4);
// insert_arr(&arr,5,333);
// append_arr(&arr,222);
// append_arr(&arr,333);
// append_arr(&arr,444);
// append_arr(&arr,555);
// append_arr(&arr,666);
// if (append_arr(&arr,123))
// {
// printf("追加成功\n");
// }
// else
// {
// printf("追加失败\n");
// }
show_arr(&arr);
//printf("%p %d %d\n",arr.pBase, arr.len, arr.cnt);
return 0;
}
//初始化数组
void init_arr(struct Arr * pArr , int length)
{
//动态分配内存
pArr -> pBase = (int *) malloc(sizeof(int) * length); //这样写导致的就是 sizeof(int) * 6 共24个字节,然后把第一个字节的地址赋值给了pBase这个指针变量,这样pBase就指向第一个元素,pBase+1就指向了第二个元素
//malloc函数如果分配不成功,比如说内存已经满了,无法再给这个pBase分配24个字节,就会把NULL赋值给pBase
if (NULL == pArr -> pBase)
{
printf("动态内存分配失败!\n");
exit(-1); //终止整个程序
}
else
{
pArr -> len = length; //相当于 (*pArr).length
pArr -> cnt = 0;
}
return;
}
//输出数组
void show_arr(struct Arr * pArr)
{
if (is_empty(pArr))
{
printf("数组为空");
}
else
{
printf("数组有效内容为:");
for (int i = 0; i < pArr -> cnt; ++i)
printf("%d ", pArr -> pBase[i]);
printf("\n");
}
}
//判断数组是否为空
bool is_empty(struct Arr * pArr)
{
if (0 == pArr -> cnt)
return true;
else
return false;
}
//判断数组是否已满
bool is_full(struct Arr * pArr)
{
if (pArr->cnt == pArr->len)
return true;
else
return false;
}
//追加元素
bool append_arr(struct Arr * pArr, int val)
{
//满时返回false
if (is_full(pArr))
{
return false;
}
//不满时追加
pArr->pBase[pArr->cnt] = val;
(pArr->cnt)++;
return true;
}
//指定位置添加元素
bool insert_arr(struct Arr * pArr, int pos, int val)
{
int i;
if (is_full(pArr))
return false;
if (pos < 1 || pos > pArr->cnt+1 )
return false;
for (i = pArr->cnt-1; i >= pos-1 ; --i)
{
pArr->pBase[i+1] = pArr->pBase[i];
}
pArr->pBase[pos-1] = val;
(pArr->cnt)++;
return true;
}
//删除指定位置元素的值
bool delete_arr(struct Arr * pArr, int pos, int * pVal)
{
int i;
if (is_empty(pArr))
return false;
if (pos < 1 ||pos > pArr->cnt+1)
return false;
*pVal = pArr->pBase[pos-1];
for (i = pos; i < pArr->cnt; ++i) {
pArr->pBase[i-1] = pArr->pBase[i];
}
(pArr->cnt)--;
printf("删除成功的元素为:%d\n",*pVal);
return true;
}
//或者指定下标元素
int get(struct Arr * pArr, int pos)
{
int result;
if (is_empty(pArr)) {
printf("数组为空");
return -1;
}
if (pos < 1 || pos > pArr->cnt+1)
{
printf("参数异常");
return -1;
}
result = pArr->pBase[pos-1];
return result;
}
//元素倒置
void inversion_arr(struct Arr * pArr)
{
int i = 0;
int j = pArr->cnt-1;
int t;
while (i<j)
{
t = pArr->pBase[i];
pArr->pBase[i] = pArr->pBase[j];
pArr->pBase[j] = t;
++i;
--j;
}
return;
}
//排序
void sort_arr(struct Arr * pArr)
{
int i,j;
int t;
for (i = 0; i < pArr->cnt; ++i)
{
for (j = i+1; j < pArr->cnt; ++j) {
if(pArr->pBase[i] > pArr->pBase[j])
{
t = pArr->pBase[i];
pArr->pBase[i] = pArr->pBase[j];
pArr->pBase[j] = t;
}
}
}
return;
}4、typedef
作用:为数据类型再多定义一个名字
/**
* @author : guqinge
* @date : 2023/12/10
* @description : typedef ,为该数据类型再定义一个名字
*/
# include <cstdio>
typedef int LIANGLILI; //为int再重新多取一个名字,LIANGLILI等价于int
typedef struct Student
{
int sid;
char name[100];
char sex;
} LiLi;
int main(void)
{
//int i = 10; //等价于 LIANGLILI i = 10;
//LIANGLILI j = 18;
//printf("%d\n",j);
struct Student st; //等价于 LiLi li;
struct Student * ps = &st; //等价于LiLi *pl;
LiLi li;
LiLi *pl = &li;
pl->sid = 123;
printf("%d\n",pl->sid);
return 0;
}/**
* @author : guqinge
* @date : 2023/12/10
* @description : typedef ,为该数据类型再定义一个名字
*/
# include <cstdio>
typedef struct Student
{
int sid;
char name[100];
char sex;
}* PST; //PST 等价于struct Student * (指针结构体)
int main(void)
{
struct Student st;
PST ps = &st;
ps->sid = 99;
printf("%d\n",ps->sid);
return 0;
}/**
* @author : Ricardo
* @date : 2023/12/10
* @description : typedef ,为该数据类型再定义一个名字
*/
# include <cstdio>
typedef struct Student
{
int sid;
char name[100];
char sex;
}* PSTU, STU; //等价于 STU代表了struct Student, PSTU代表了struct Student *
int main(void)
{
STU st; //struct Student st;
PSTU ps = &st; //struct Student * ps = & st;
ps->sid = 99;
printf("%d\n",ps->sid);
return 0;
}2、离散存储[链表]
1、定义
n个节点离散分配
彼此通过指针相连
每个节点只有一个前驱节点,每个节点只有一个后续节点
首节点没有前驱节点,尾节点没有后续节点
专业术语:
首节点
第一个有效节点
尾节点
最后一个有效节点
头结点
头结点的数据类型和首节点类型一样
第一个有效节点之前的那个节点
头结点并不存放有效数据
加头结点的目的主要是为了方便对链表的操作
头指针
指向头结点的指针变量
尾指针
指向尾节点的指针变量
如果希望通过一个函数来对链表进行处理,我们至少需要接收链表的哪些参数:
只需要一个参数:头指针
因为我们通过头指针可以推算出链表的其它所有信息
一个节点的生成
/**
* @author : guqinge
* @date : 2023/12/11
* @description : 一个节点的生成
*/
# include <cstdio>
struct Node
{
int data; //数据域
struct Node * pNext; //指针域 (因为指向的是下一个数据类型和它一样的一个整体的节点,所以是 struct Node * 类型)
}NODE, *PNODE; //NODE等价于struct Node, PNODE等价于 struct Node *
int main(void)
{
return 0;
}
插入一个节点
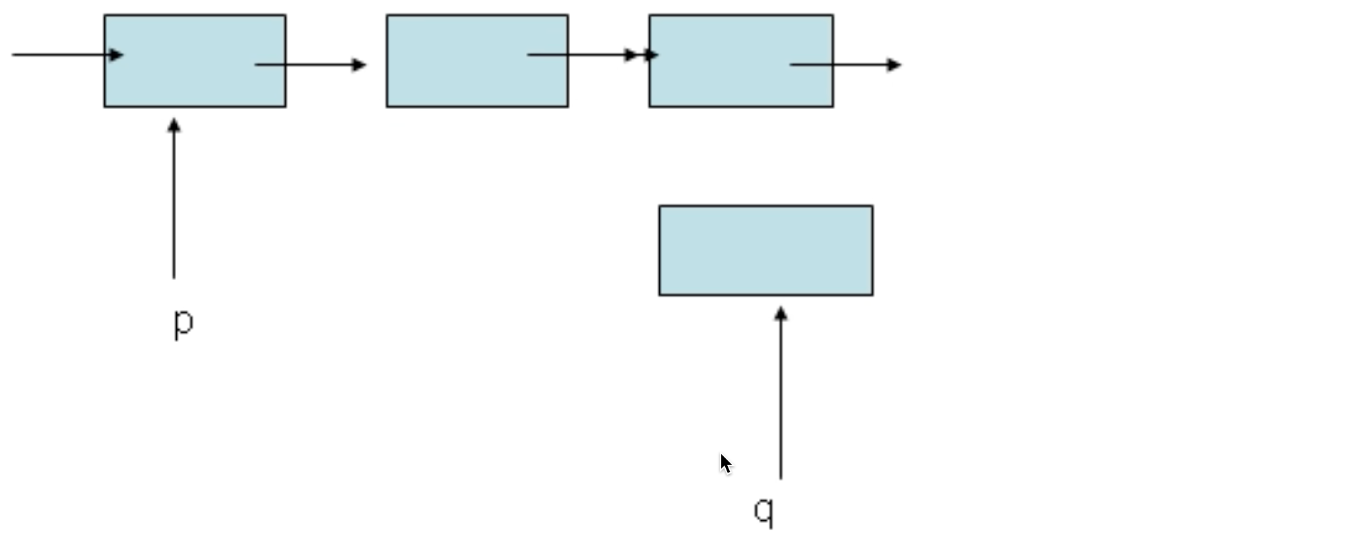
如图,将q插入到p的后面
q->pNext = p->pNext; //p的指针域存放的是下一个节点的地址,将这个节点的地址赋给q的指针域,那么q的指针域就存放了这个节点的地址了
p->pNext=q; //再将q的地址赋值给p的指针域,那么p就指向了q这个节点,这样就完成了再p的后面插入一个节点q了
2、分类
单链表
非循环单链表
创建一个链表PNODE create_list(void)
指定位置插入链表bool insert_list(PNODE pHead, int position, int val)
双链表
每一个节点有两个指针域
循环链表
能通过任何一个节点找到其它所有的节点
非循环链表
3、算法
/**
* @author : guqinge
* @date : 2023/12/12
* @description :
*/
# include <cstdlib>
# include <cstdio>
typedef struct Node
{
int data; //数据域
struct Node * pNext; //指针域
}NODE, *PNODE; //NODE等价于struct Node, PNODE等价于struct Node *
//函数声明
PNODE create_list(void);
void traverse_list(PNODE pHead);
bool is_empty(PNODE pHead);
int length_list(PNODE pHead);
bool insert_list(PNODE pHead, int position, int val); //在pHead所指向链表的第position个节点的前面插入一个新的节点,该结点的值是val,并且position的值是从1开始
bool delete_list(PNODE pHead, int position, int * delVal);
void sort_list(PNODE pHead);
int main(void)
{
PNODE pHead = NULL; //等价于 struct Node * pHead = NULL;
int val;
pHead = create_list(); //create_list()功能:创建一个非循环单链表,并将该链表的头节点的地址赋给pHead
insert_list(pHead, 2, 33);
if (delete_list(pHead, 4, &val))
{
printf("删除成功,您删除的元素时:%d\n", val);
} else
{
printf("删除失败!您删除的元素不存在!\n");
}
sort_list(pHead);
traverse_list(pHead);
if (is_empty(pHead))
printf("链表为空!\n");
else
printf("链表非空!\n");
int len = length_list(pHead);
printf("链表长度为:%d\n", len);
return 0;
}
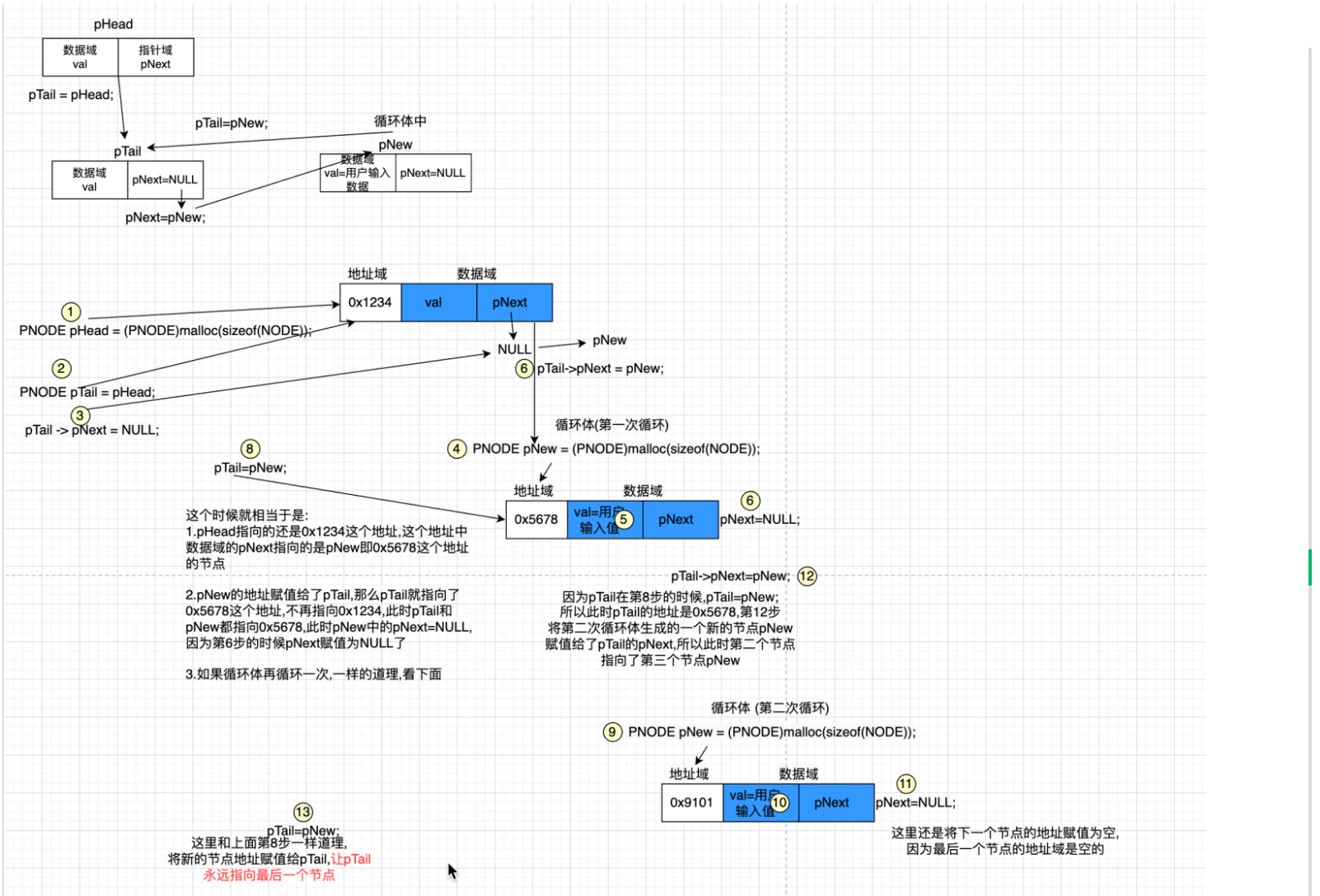
PNODE create_list(void)
{
int len; //用来存放有效节点的个数
int i;
int val; //用来临时存放用户输入的节点的值
PNODE pHead = (PNODE)malloc(sizeof(NODE)); //分配了一个不存放有效数据的头节点
if (NULL == pHead)
{
printf("内存分配失败,程序终止!\n");
exit(-1);
}
PNODE pTail = pHead;
pTail->pNext = NULL;
printf("请输入您需要生成的链表节点的个数:len= ");
scanf("%d", &len);
for (i = 0; i < len; ++i)
{
printf("请输入第%d个节点的值:", i+1);
scanf("%d", &val);
PNODE pNew = (PNODE) malloc(sizeof(NODE));
if (NULL == pNew)
{
printf("内存分配失败,程序终止!\n");
exit(-1);
}
pNew->data = val;
pTail->pNext = pNew;
pNew->pNext = NULL; //最后一个节点的指针域是空的
pTail = pNew;
}
return pHead;
}
void traverse_list(PNODE pHead)
{
PNODE p = pHead->pNext;
while (nullptr != p)
{
printf("%d ", p->data);
p = p->pNext;
}
printf("\n");
return;
}
//判断链表是否为空
bool is_empty(PNODE pHead)
{
if (NULL == pHead->pNext)
return true;
else
return false;
}
//链表长度
int length_list(PNODE pHead)
{
PNODE p = pHead->pNext;
int count = 0;
while (NULL != p)
{
p = p->pNext;
count++;
}
return count;
}
//链表排序
void sort_list(PNODE pHead)
{
//数组选择排序
// int i, j, t;
//
// for (i = 0; i < len - 1; ++i)
// {
// for (j = i+1; j < len; ++j)
// {
// if (a[i] > a[j])
// {
// t = a[i];
// a[i] = a[j];
// a[j] = t;
// }
// }
// }
//链表选选择排序
int i, j, t;
int len = length_list(pHead);
PNODE p, q;
for (i=0, p=pHead->pNext; i < len - 1; ++i, p=p->pNext)
{
for (j = i+1, q=p->pNext; j < len; ++j ,q=q->pNext)
{
if (p->data > q->data) //类似于数组中的: a[i] > a[j]
{
t = p->data; //类似于数组中的: t = a[i];
p->data = q->data; //类似于数组中的: a[i] = a[j];
q->data = t; //类似于数组中的: a[j] = t;
}
}
}
return;
}
//在pHead所指向链表的第position个节点的前面插入一个新的节点,该结点的值是val,并且position的值是从1开始
bool insert_list(PNODE pHead, int position, int val)
{
int i = 0;
PNODE p = pHead;
//移动到插入位置的前一个节点
while (NULL != p && i < position - 1)
{
p = p -> pNext;
++i;
}
//判断是否找到了合适的位置
if (i > position - 1 || NULL == p)
return false;
//动态分配新节点
PNODE pNew = (PNODE) malloc(sizeof(NODE));
if (NULL == pNew)
{
printf("动态分配内存失败!\n");
exit(-1);
}
//初始化新节点
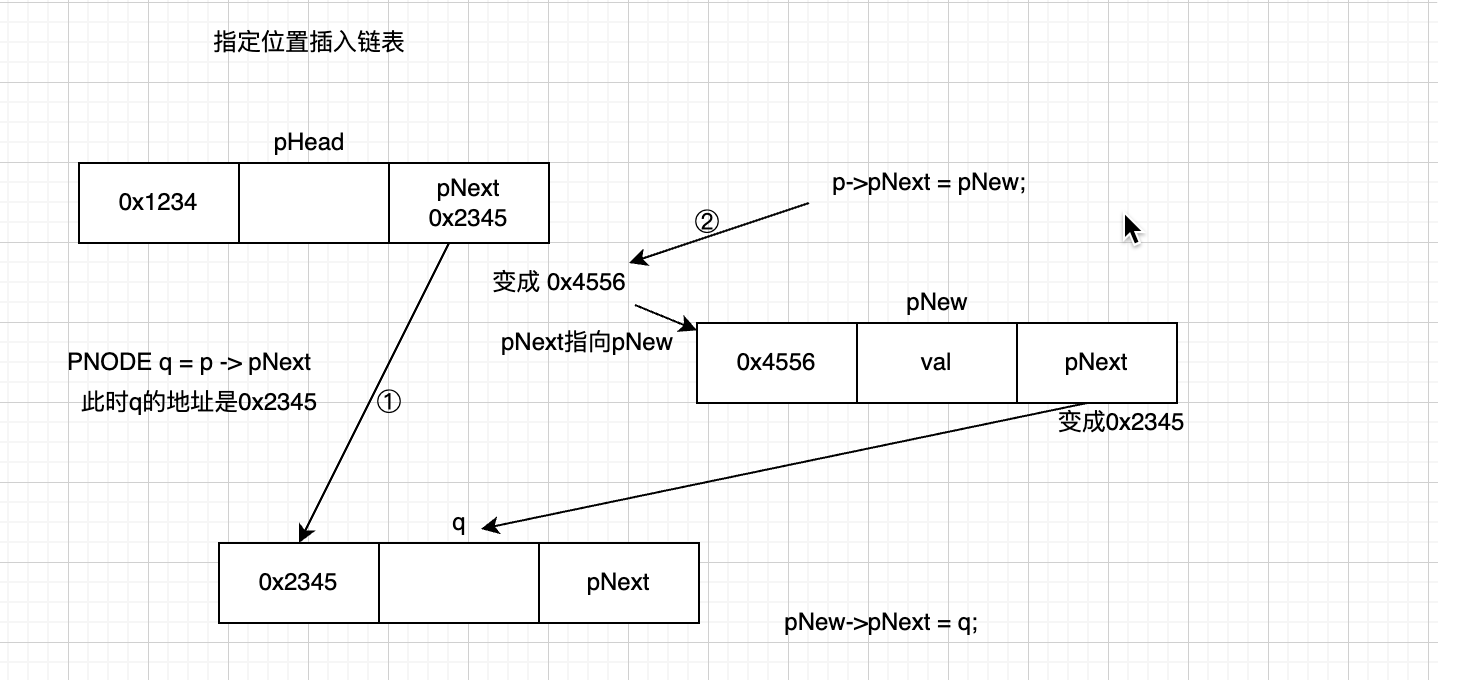
/**
* 1. pNew -> data = val;
* - 这一行将新创建的节点 pNew 的数据域 data 赋值为传入的参数 val,即将新节点的数据设置为需要插入的值。
* 2. PNODE q = p -> pNext;
* - 这一行创建一个临时指针 q,并将其指向原本在插入位置的节点的下一个节点。这是因为在插入新节点时,需要保持链表的连接关系。
* 3. p -> pNext = pNew;
* - 这一行将原本在插入位置的节点(由指针 p 指向的节点)的指针域 pNext 指向新创建的节点 pNew。这样,新节点就被插入到链表中了。
* 4. pNew -> pNext = q;
* - 最后一行将新节点 pNew 的指针域 pNext 指向之前保存的临时指针 q,即将新节点与原来的链表连接起来。
*/
pNew -> data = val;
PNODE q = p -> pNext;
p -> pNext = pNew;
pNew -> pNext = q;
return true;
}
bool delete_list(PNODE pHead, int position, int * delVal)
{
int i = 0;
PNODE p = pHead;
// 移动到待删除节点的前一个节点
while (NULL != p->pNext && i < position - 1)
{
p = p -> pNext;
++i;
}
// 判断是否找到了合适的位置
if (i > position - 1 || NULL == p->pNext)
return false;
// 保存待删除节点的引用和值
PNODE q = p -> pNext;
*delVal = q ->data;
//删除p节点后面的节点
/**
* 1. p->pNext = p->pNext->pNext;
* - p 是指向待删除节点前一个节点的指针。
* - p->pNext 是待删除节点。
* - p->pNext->pNext 是待删除节点的下一个节点。
* 这一行的目的是将待删除节点的前一个节点的指针 pNext 直接跳过待删除节点,指向待删除节点的下一个节点,从而删除了待删除节点。
* 2. free(q);
* - q 是指向待删除节点的指针。
* - free(q) 用于释放待删除节点的内存,以防止内存泄漏。
* 3. q = NULL;
* - 将指针 q 设为 NULL,以确保不会再意外地使用已经释放的内存。
*/
p -> pNext = p -> pNext -> pNext;
free(q);
q = NULL;
return true;
}遍历
查找
清空
销毁
求长度
排序
删除节点
插入节点
算法:
狭义的算法是与数据的存储方式密切相关
广义的算法是与数据的存储方式无关
泛型:
利用某种技术达到的效果就是:不同的存储方式,执行的操作是一样的
4、链表的优缺点
3、线性结构的两种常见应用之一 栈
定义:
一种可以实现 ”先进后出“ 的存储结构
栈类似于弹匣
栈的分类:
静态栈
概念
静态栈是一种固定大小的栈数据结构,其大小在创建时确定,不能动态改变。静态栈使用一个数组来存储数据元素,通常分配的空间是固定的,因此在某些情况下,可能会导致栈溢出。静态栈的大小在编译时就已知,这使得它更适合一些特定的应用场景。
特点
固定大小:静态栈的大小在创建时确定,无法在运行时改变。
使用数组:数据元素存储在数组中,栈顶指针(top)指向栈顶元素。
风险:可能会发生栈溢出,当栈已满时继续入栈会导致数据丢失。
示例:
#include <stdio.h>
#define MAX_SIZE 10
// 静态栈结构
typedef struct
{
int data[MAX_SIZE]; // 存储栈元素的数组
int top; // 栈顶指针,指向最后一个元素的位置
} StaticStack;
// 初始化静态栈
void initialize(StaticStack *stack)
{
stack->top = -1; // 初始化栈顶指针为-1,表示栈为空
}
// 入栈操作
void push(StaticStack *stack, int value)
{
if (stack->top < MAX_SIZE - 1)
{ // 检查栈是否已满
stack->data[++stack->top] = value; // 栈顶指针加一,然后将值存储在新栈顶位置
printf("入栈:%d\n", value); // 输出入栈的值
}
else
{
printf("栈已满,无法入栈\n");
}
}
// 出栈操作
int pop(StaticStack *stack)
{
if (stack->top >= 0)
{ // 检查栈是否为空
int popped_value = stack->data[stack->top--]; // 弹出栈顶元素,同时栈顶指针减一
printf("出栈:%d\n", popped_value); // 输出出栈的值
return popped_value;
}
else
{
printf("栈已空,无法出栈\n");
return -1; // 返回-1表示栈为空
}
}
// 输出栈中的元素
void display(StaticStack *stack)
{
if (stack->top == -1)
{
printf("静态栈为空\n");
}
else
{
printf("静态栈中的元素: ");
for (int i = 0; i <= stack->top; i++)
{
printf("%d ", stack->data[i]);
}
printf("\n");
}
}
int main()
{
StaticStack stack;
initialize(&stack); // 初始化静态栈
push(&stack, 1); // 入栈操作
push(&stack, 2);
push(&stack, 3);
display(&stack); // 输出栈中的元素
int popped_item = pop(&stack); // 出栈操作
printf("出栈: %d\n", popped_item);
display(&stack); // 再次输出栈中的元素
return 0;
}动态栈
概念
动态栈是一种栈数据结构,其大小在运行时动态分配和释放内存,可以根据需要自动扩展或缩小,动态栈使用指针和动态内存分配。
特点
动态大小:动态栈的大小可以根据需要动态增加或减小。
使用指针:数据元素存储在动态分配的内存中,栈顶指针(top)指向栈顶元素。
动态分配:内存分配由程序员控制,可以避免栈溢出的问题。
示例
#include <stdio.h>
#include <stdlib.h>
// 动态栈结构
typedef struct
{
int *data; // 存储栈元素的数组
int top; // 栈顶指针,指向最后一个元素的位置
int capacity; // 栈的容量,即数组大小
} DynamicStack;
// 初始化动态栈
void initialize(DynamicStack *stack, int capacity)
{
stack->data = (int *)malloc(sizeof(int) * capacity); // 动态分配内存
stack->top = -1; // 初始化栈顶指针为-1,表示栈为空
stack->capacity = capacity; // 设置栈的容量
}
// 入栈操作
void push(DynamicStack *stack, int value)
{
if (stack->top < stack->capacity - 1)
{
stack->data[++stack->top] = value; // 栈顶指针加一,然后将值存储在新栈顶位置
printf("入栈:%d\n", value); // 输出入栈的值
}
else
{
printf("栈已满,无法入栈\n");
}
}
// 出栈操作
int pop(DynamicStack *stack)
{
if (stack->top >= 0)
{
int popped_value = stack->data[stack->top--]; // 弹出栈顶元素,同时栈顶指针减一
printf("出栈:%d\n", popped_value); // 输出出栈的值
return popped_value;
}
else
{
printf("栈已空,无法出栈\n");
return -1; // 返回-1表示栈为空
}
}
// 输出栈中的元素
void display(DynamicStack *stack)
{
if (stack->top == -1)
{
printf("动态栈为空\n");
}
else
{
printf("动态栈中的元素: ");
for (int i = 0; i <= stack->top; i++)
{
printf("%d ", stack->data[i]);
}
printf("\n");
}
}
int main()
{
int capacity = 5;
DynamicStack stack;
initialize(&stack, capacity); // 初始化动态栈
push(&stack, 1); // 入栈操作
push(&stack, 2);
push(&stack, 3);
display(&stack); // 输出栈中的元素
int popped_item = pop(&stack); // 出栈操作
display(&stack);
free(stack.data); // 释放动态分配的内存
return 0;
}
算法
压栈
弹栈
栈程序演示(动态栈,和上面的差不多)
/**
* @author : guqingge
* @date : 2024/2/1
* @description :
*/
# include "cstdio"
# include "cstdlib"
typedef struct Node
{
int data;
struct Node * pNext;
}NODE, *PNODE; //
typedef struct Stack
{
PNODE pTop;
PNODE pBottom;
}STACK, *PSTACK ; //PSTACK 等价于 struct STACK *
void init(PSTACK pStack); //初始化栈
void push(int val, PSTACK pStack); //压栈
void pop(PSTACK pStack); //弹栈
void traverse(PSTACK pStack); //遍历
int main()
{
STACK S; //STACK 等价于 struct Stack;
PSTACK pStack = &S;
init(pStack); //初始化栈
push(1, pStack); //压栈(添加元素)
push(3, pStack); //压栈(添加元素)
push(4, pStack); //压栈(添加元素)
pop(pStack); //弹栈
pop(pStack); //弹栈
traverse(pStack); //遍历
return 0;
}
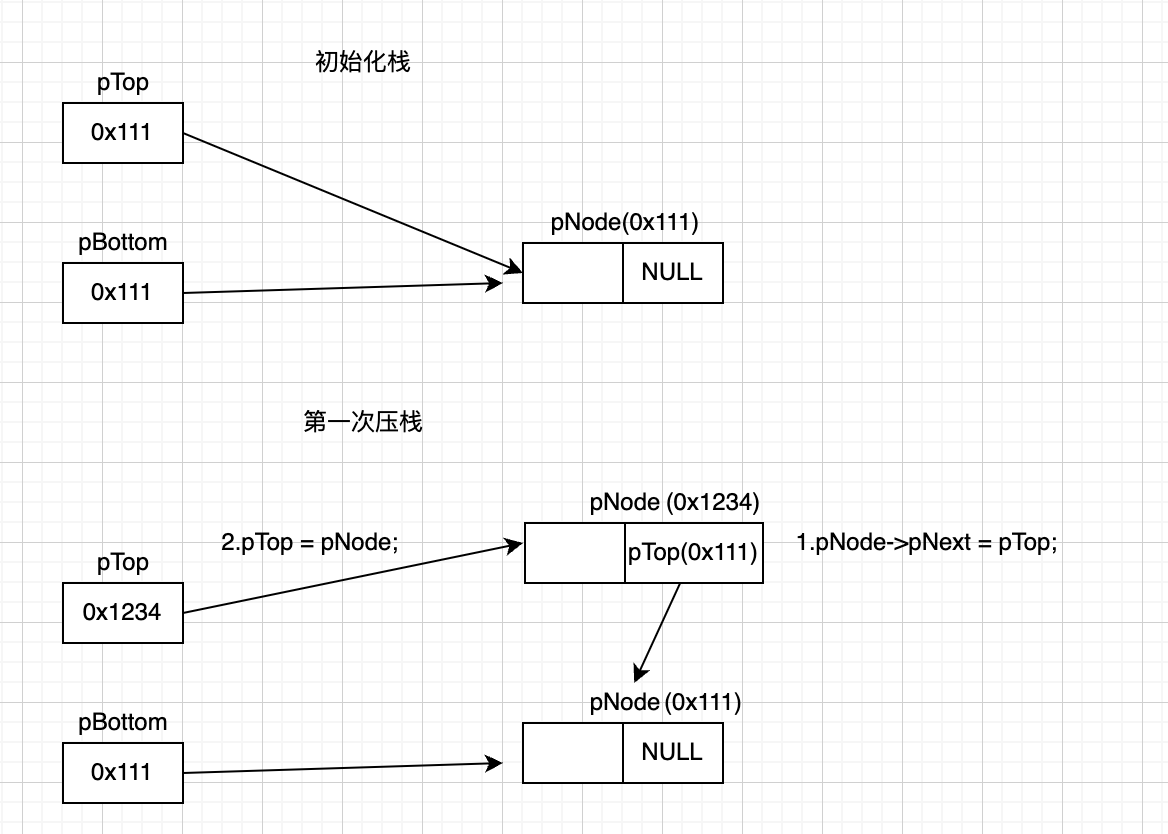
//初始化栈
void init(PSTACK pStack)
{
PNODE pNode = (PNODE)malloc(sizeof(Node));
if (NULL == pNode)
{
printf("动态内存分配失败!\n");
exit(-1);
}
pStack->pTop = pNode;
pStack->pBottom = pNode;
pNode->pNext = NULL; //就是pBottom指向的是最后一个节点,最后一个节点的pNext应该是空的
}
//压栈
void push(int val, PSTACK pStack)
{
PNODE pNode = (PNODE) malloc(sizeof(NODE));
if (NULL == pNode)
{
printf("动态内存分配失败!\n");
exit(-1);
}
pNode->data = val;
pNode->pNext = pStack->pTop;
pStack->pTop = pNode;
}
//弹栈
void pop(PSTACK pStack)
{
if (pStack->pTop == pStack->pBottom)
{
printf("栈为空栈!\n");
}
PNODE r = pStack->pTop;
pStack->pTop = r->pNext;
free(r);
r = NULL;
return;
}
//遍历
void traverse(PSTACK pStack)
{
PNODE pTop = pStack->pTop;
PNODE pBottom = pStack->pBottom;
int val;
if (pTop == pBottom){
printf("栈为空栈");
}
while (pBottom != pTop){
val = pTop->data;
printf("%d\n",val);
pTop = pTop->pNext;
}
return;
}
//清空
void clear(PSTACK pStack)
{
if (pStack->pTop == pStack->pBottom)
{
printf("栈为空栈!\n");
}
PNODE p = pStack->pTop;
PNODE q = NULL;
while (p != pStack->pBottom)
{
q = p->pNext;
free(p);
p = q;
}
pStack->pTop = pStack->pBottom;
}应用
函数调用(压栈、出栈)
中断
表达式求值
内存分配
缓冲处理
迷宫
4、线性结构的两种常见应用之二 队列
定义:
一种可以实现 ”先进先出“ 的存储结构
分类:
链式队列
链表实现
静态队列
数组实现
静态队列通常都必须是循环队列
循环队列:
循环队列的讲解:
1、静态队列为什么必须是循环队列
2、循环对需要几个参数来确定
3、循环队列各个参数的含义
4、循环队列的入队伪算法讲解
5、循环队列出队伪算法讲解
6、如何判断循环队列是否为空
7、如何判断循环队列是否已满

.jpg)
.jpg)


.jpg)
.jpg)